MapReduce Paper Review
Introduction
MapReduce is a software architecture model first proposed by Google, enabling large-scale data processing in parallel. Today, this concept has been adopted by countless distributed systems.
The relevant theory was published by Google in their 2004 paper, “MapReduce: Simplified Data Processing on Large Clusters,” which you can read in full here. Despite being only 13 pages long, this paper is so densely packed with information that it easily outshines many other academic works.
These notes were written as I read through the paper, so the content may seem somewhat fragmented.
Programming Model
MapReduce is a very straightforward parallel processing model. When using the MapReduce framework, the user only needs to define two functions:
- The Map function, which transforms a single key-value pair into a series of intermediate key-value pairs.
- The Reduce function, which aggregates all intermediate values associated with the same key.
Everything else—data distribution, task assignment, fault tolerance, load balancing, and so on—is handled by the framework. This allows users to focus squarely on the business logic without having to worry about implementation details.
The typical data flow looks like this:
The Map function takes an input key-value pair and produces a series of intermediate key-value pairs. The MapReduce framework groups all intermediate values with the same key and passes them to the Reduce function. The Reduce function takes an intermediate key and its associated list of values, and typically aggregates these values into a smaller set. Each invocation of Reduce usually produces a single output value, and sometimes may produce none at all.
A classic example is counting word occurrences in a large text corpus:
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
emit intermediate (w, "1")
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for v in values:
result += ParseInt(v);
emit (ToString(result));Implementation
Execution Flow
As a programming model—or, more accurately, as a programming paradigm—MapReduce can be implemented in various ways. Google’s paper describes a particular implementation designed for clusters of machines connected over a local network. The process is illustrated below:
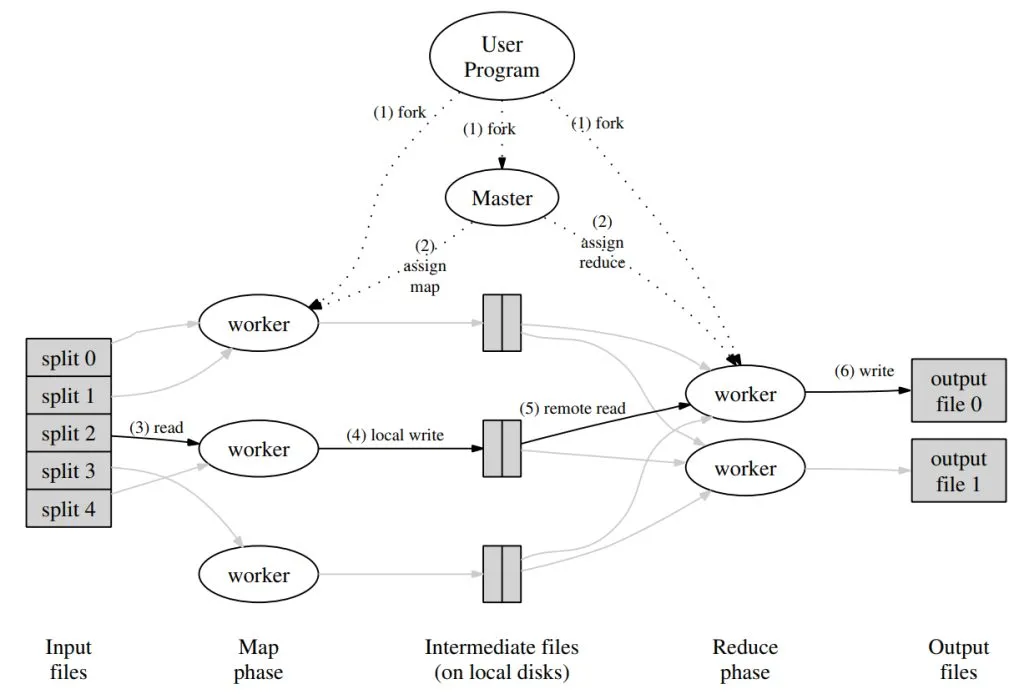
- First, the MapReduce framework divides the input file into M splits, typically sized between 16MB and 64MB. Then, it launches processes on the machines in the cluster.
- One of these processes acts as a special master process, while the remaining processes serve as workers managed by the master. The master coordinates the assignment of M map tasks and R reduce tasks. Idle worker processes are assigned one task at a time, either map or reduce.
- A worker assigned a map task reads its input split, parses it into key-value pairs, and applies the user-defined Map function to each pair. The intermediate key-value pairs returned by the Map function are buffered in memory.
- Periodically, the worker partitions its buffered key-value pairs into R splits (using a partition function), and writes each split to local disk. The locations of these partitions on disk are reported to the master, which then relays the information to the appropriate reduce workers.
- When a reduce worker is notified of these locations by the master, it fetches the relevant intermediate data directly from the map workers via RPC. Once a reducer has read all intermediate data, it sorts the data by key so that records with the same key are grouped together. Sorting is necessary because single reduce tasks may be responsible for many distinct keys, and, if the data is too large, external sorting may be used.
- The reduce worker then iterates over the sorted data; for each unique key it finds, it invokes the user-defined Reduce function with the key and its associated list of values. The output of the Reduce function is appended to the final output file (one output file per reduce partition).
- When all map and reduce tasks are complete, the MapReduce job finishes.
After the job completes, the results are stored in R output files, which are usually used as input for subsequent MapReduce jobs.
Fault Tolerance
Here, we’ll focus on worker failures, rather than master failures (the latter requires consensus and leader election, which are more complex topics).
The master and workers maintain a heartbeat mechanism; if a worker fails to respond within a certain timeframe, it is presumed dead. Any map tasks completed by the failed worker are marked as not started and will be rescheduled to other workers. Any in-progress map or reduce tasks on a failed worker are also marked as not started.
Previously completed map tasks need to be rerun because their results were stored on the local disk of a failed machine, whereas completed reduce tasks do not need to be rerun because their outputs are written to a globally accessible file system.
If a map task was initially executed by worker A, and A crashes, the task is reassigned to worker B. The master notifies all reduce workers about this change; any reduce worker that hasn’t yet fetched the data from A will instead fetch it from B.
Another challenge: sometimes certain machines are very slow, but not unresponsive enough to be declared dead. These so-called “stragglers” can become bottlenecks, causing the entire job to stall while waiting for the slowest node to finish. Google’s implementation addresses this by, near the end of the MapReduce operation, assigning backup copies of any remaining tasks to idle workers. As soon as either the original or the backup task finishes, the result is accepted and the task is considered successfully completed.
At this point, smaller optimizations and enhancements are left out for brevity.