MapReduce 論文読解
はじめに
MapReduce は Google が初期に提唱したソフトウェアアーキテクチャモデルで、大規模データセットの並列処理をサポートします。現在、この概念は多くの分散システムで活用されています。
関連理論は Google が 2004 年に発表した論文『MapReduce: Simplified Data Processing on Large Clusters』に詳述されており、こちら から全文を読むことができます。13 ページの短い論文ですが、情報密度は非常に高いです。
本記事は論文を読みながらメモを取ったものであるため、内容がやや散漫になる可能性があります。
プログラミングモデル
MapReduce は非常にシンプルな並列処理モデルで、MapReduce フレームワークを用いることでユーザーは二つの関数を指定するだけで済みます。
- Map 関数:一つのキー・バリュー対を一連の中間キー・バリュー対に変換する役割
- Reduce 関数:同じキーを持つすべての中間値を統合する役割
残りの処理はフレームワークが自動的に担当し、データ配布、タスク割り当て、エラー処理、負荷分散などの詳細はユーザーが気にする必要はありません。ユーザーはビジネスロジックに集中できます。
大まかな処理の流れは以下の通りです。
Map は入力のキー・バリュー対を受け取り、一連の中間キー・バリュー対を生成します。MapReduce フレームワークは同じ中間キーを持つ値をまとめて Reduce 関数に渡します。Reduce 関数は中間キーとその一連の値を受け取り、通常はそれらを集約してより小さな集合にします。場合によっては、Reduce 関数の呼び出しごとに一つの結果値を返すか、結果を返さないこともあります。
大規模なテキストの単語数カウントを例にすると:
map(String key, String value):
// key:文書名
// value:文書内容
for 単語 w in value:
中間カウント (w, "1") を増やす
reduce(String key, Iterator values):
// key:単語
// values:一連のカウント
int result = 0;
for v in values:
result += ParseInt(v);
出力 (ToString(result))実装
実行フロー
MapReduce はプログラミングモデル、あるいはプログラミング思想として多様な実装が可能です。Google は論文中で、ローカルネットワーク内で接続された多数のマシンを用いる一つの実装方法を示しています。実行フローは以下の図の通りです。
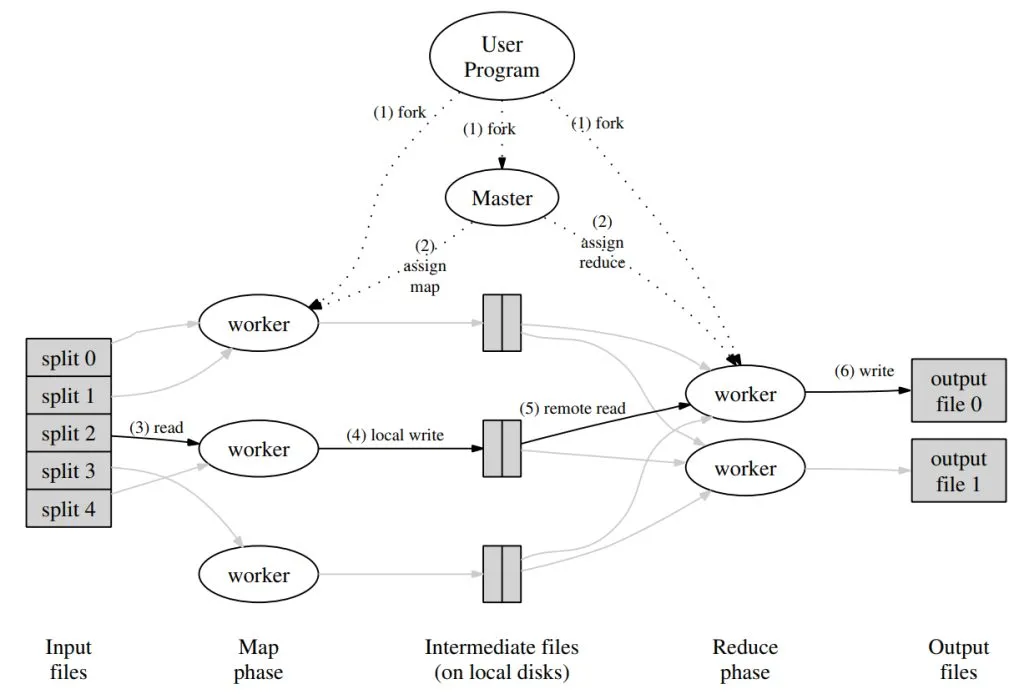
- MapReduce フレームワークはまず入力ファイルを M 個のチャンクに分割します。各チャンクのサイズは通常 16MB から 64MB です。その後、クラスタ内のマシン(プロセス)を起動します。
- クラスタ内の一つのプロセスは特別な master プロセスで、残りの worker プロセスにタスクを割り当てます。M 個の map タスクと R 個の reduce タスクがあり、master は空いている worker を選んで一つずつ map または reduce タスクを割り当てます。
- map タスクを割り当てられた worker は対応するチャンクの入力を読み込み、キー・バリュー対を解析し、ユーザー定義の map 関数に渡します。map 関数が返す中間キー・バリュー対は一時的にメモリにキャッシュされます。
- worker のメモリにキャッシュされたキー・バリュー対は分割関数により R 個のチャンクに分割され、定期的にローカルディスクに書き込まれます。これらのディスク上の位置情報は master に送られ、master は reduce タスクに割り当てられた worker に位置情報を通知します。
- reduce worker は master から位置情報を受け取ると、対応する map worker に RPC リクエストを送りデータを読み込みます。すべての中間データを読み終えたら、key ごとにソートし、同じ key のデータをまとめます。このソートは必要で、なぜなら多くの異なる key が一つの reduce タスクで処理されるためです。データが大きい場合は外部ソートが使われます。
- reduce worker はソート済みの中間データを走査し、出現するすべての key と対応する値の集合をユーザー定義の reduce 関数に渡します。reduce 関数の出力は最終出力ファイル(reduce チャンクごとに一つ)に追記されます。
- すべての map タスクと reduce タスクが完了すると、MapReduce の処理も終了します。
処理終了後、MapReduce の結果は R 個の出力ファイルに保存され、通常は次の MapReduce タスクの入力として使われます。
フォールトトレランス
ここでは worker の故障のみを考慮し、master の故障は扱いません。master の故障は選挙やコンセンサスなど複雑な問題を含むためです。
master と worker はハートビートを維持し、一定時間内に worker からの応答がなければその worker は故障とみなされます。この worker が完了した map タスクは未開始状態に戻され、他の worker に再割り当てされます。故障時に進行中だった map または reduce タスクも未開始にマークされます。
完了済みの map タスクを再実行する必要があるのは、その結果が故障したマシンのローカルディスクに保存されているためです。一方、完了済みの reduce タスクはグローバルファイルシステムに結果が保存されているため再実行は不要です。
ある map タスクが最初に A に割り当てられ、A が故障して B に再割り当てされた場合、この情報はすべての reduce タスクの worker に通知されます。まだ A からデータを読み込んでいない reduce タスクは B から読み込むよう切り替えます。
時折、性能の低いマシンがネットワークは正常なため故障判定されず、システム全体のボトルネックになることがあります。この問題に対して、Google の実装では MapReduce 処理の終盤に master がまだ進行中のタスクを他の空き worker に再割り当てします。元の worker か再割り当て先のどちらかがタスクを完了すれば、そのタスクは成功と見なされます。
性能向上や小規模な最適化・拡張については割愛します。