

1. 计算机硬件
计算机硬件组成
- 基本硬件系统:运算器、控制器、存储器、输入设备、输出设备
- 运算器、控制器等集成在一起为 CPU,完成数据加工、算术、逻辑运算和控制功能等
- 存储器:记忆设备,分为内部存储器和外部存储器
- 输入设备和输出设备合称为外部设备
CPU
- CPU 的功能:
- 程序控制
- 操作控制
- 时间控制
- 数据处理
- 对内部和外部中断(异常)作出响应
- CPU的组成:运算器、控制器、寄存器组和内部总线等
- 运算器:由算数逻辑单元 ALU、累加寄存器 AC(暂存源操作数和结果)、数据缓冲寄存器 DR 和状态条件寄存器 PSW,执行所有的算术运算和逻辑运算
- 控制器:由指令寄存器 IR、程序计数器 PC、地址寄存器 AR、指令译码器 ID 等组成
- CPU 根据指令周期的不同阶段来区分二进制的指令和数据
校验码
码距:在两个编码中,从 A 码到 B 码转化所需要改变的位数。越大越利于纠错和检错
奇偶校验码:增加 1 位校验位来使编码中1的个数为奇数(奇校验)或者偶数(偶校验),从而使码距变为 2
奇偶校验只能检出 1 位错,且无法纠错
循环冗余校验码 CRC:只能检错不能纠错
先约定一个生成多项式 G(x),在原始信息位后追加若干校验位,使得追加的信息能被 G(x) 整除。接收方接收到带校验位的信息若能整除则没有错误
==示例(重要)==:
原始信息串 10110,CRC 的生成多项式为
$$$ G(x)=x^4+x+1 $$$
,求 CRC 校验码
在原始信息位后面加 r 个 0,r 为多项式的阶。本题加 4 个 0,得到 101100000,作为被除数
由多项式得到除数,多项中 x 的幂指数存在的位置为 1,不存在的位置为 0。本题中,x 的 0、1、4 次幂都存在,得到串 10011
生成 CRC 校验码,将前两步得到的被除数和除数进行模 2 除法运算(除法操作时进行异或操作),得到余数 1111。若余数不足 r,左侧以 0 补齐
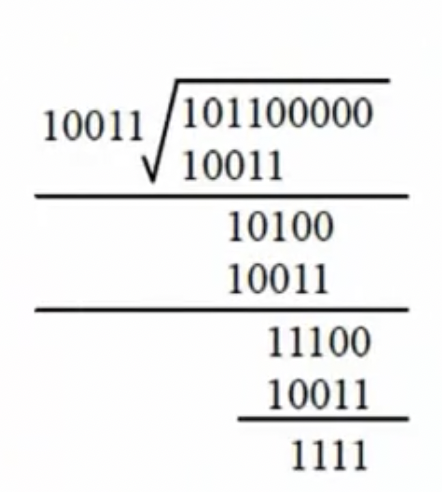
将余数添加到原始信息后生成最终信息串
接收方校验,以最终信息串为被除数,同 2 得到除数,余数为 0 则信息无错
指令系统
- 指令组成:操作码 + 操作数,操作码决定要完成的操作,操作数指参与预算的数据及其所在的单元地址
- 指令执行流程:取指令 — 分析指令 — 执行指令
- 指令寻址方式:
- 顺序:按顺序执行
- 跳跃:非 PC 给出,而由本条指令给出
- 操作数寻址方式:
- 立即寻址方式:指令直接给出立即数
- 直接寻址方式:指令直接给出操作数的地址
- 间接寻址方式:指令地址码字段指向的存储单元存储的是操作数的地址
- 寄存器寻址方式:地址码是寄存器编号
- 基指寻址方式:基址寄存器内容加指令中的地址得到操作数地址
- 变址寻址方式:变址寄存器内容加指令中的地址得到操作数地址
- CISC 复杂指令系统,通过微程序控制技术(微码)实现
- RISC 精简指令系统,增加通用寄存器,硬布线逻辑控制实现为主
- Flynn 分类法根据指令流和数据流的不同组合,将计算机分为 4 类。当前主流的为 MIMD(多指令流多数据流)
- 流水线原理:指令分段,每段由不同部分处理
- RISC 中的流水线技术:
- 超流水线技术:细化流水、增加级数和提高主频,使得每个机器周期完成一个到两个浮点操作,本质是时间换空间
- 超标量技术:内装多条流水线来同时执行多个处理,CPI 更小,本质是空间换时间
- 超长指令字技术:发挥软件的作用,使得硬件简化进行性能提高
- ==流水线时间计算==
- 流水线周期:指令分段,最长段即为流水线周期
- 流水线执行时间:1条指令总执行时间 +(总指令条数-1)* 流水线周期
- 流水线吞吐率:即单位时间内执行的指令条数。指令条数/流水线执行时间
- 流水线加速比:使用流水线后的效率提升度,不使用流水线的执行时间/使用流水线的执行时间


存储系统
- 局部性原理:CPU 运行时,所访问的数据会趋向于一个较小的局部空间地址内,包括
- 时间局部性:相邻的时间访问同一个数据项
- 空间局部性:相邻的空间地址会被连续访问
- 高速缓存 Cache 存储房钱最活跃的程序和数据,直接与 CPU 交互,位于 CPU 和主存之间
- Cache 由控制部分和存储器组成
- 地址映射:在 CPU 工作时,送出的是主存单元的地址,而应从 Cache 存储器中读写信息,需要将主存地址转换为 Cache 存储器地址,由硬件完成,分为下列三种方法
- 直接映像:将 cache 存储器分成块,主存也分成块, 通常直接模运算,二者块号相同才能命中,简单不灵活
- 全相联映像:同样分块并编号,主存中的任意一块都与 Cache 中的任意一块对应,可以随意调入 Cache 任意位置,地址变换复杂,最不容易发生冲突
- 组相联映像:两种方法结合,Cache 先分块再分组,主存也分块分组,组间采用直接映像,组号相同才命中,但组内全相联,组号相同的两个组内所有块可以任意调换
- Cache 替换算法:目标尽可能高的命中率
- 随机替换
- 先进先出
- 近期最少使用,LFU
- 优化替换,先执行一次程序,统计 Cache 的替换情况
- Cache 命中率与平均时间,假设命中率为 v,从 cache 读取需要花费 a 时间,从主存花费 b 时间,则平均读取时间为 v*a + (1-v)*b
- 磁盘结构:正反两个盘面,每个盘面多个磁道,每个磁道被划分成多个扇区,数据就存放在扇区中
- 磁头首先找到对应磁道,再等待磁盘进行周期旋转到指定扇区读取
- 存取时间 = 寻道时间 + 等待时间(即平均定位时间 + 转动延迟),寻道时间耗时最长
- 寻道调度算法:
- 先来先服务 FCFS
- 最短寻道时间优先 SSTF
- 扫描算法 SCAN:一直处理完某个方向的请求后才会调头
- 单向扫描调度算法 CSCAN:只做单向移动,一直到顶后掉头(非处理完某方向全部请求后掉头)

输入输出技术
- 内存与接口地址的编址方法
- 内存与接口地址独立编址方法:完全独立地址空间,指令也不同。缺点是用于接口的指令太少、功能太弱
- 内存与接口地址统一编址方法:统一在一个公共的地址空间。原则上用于内存的指令全都可用于接口。缺点是整个地址空间被分为两部分
- 计算机和外设的交互方式
- 程序控制(查询):CPU 主动查询外设是否完成数据传输,效率极低
- 程序中断:外设完成后向 CPU 发送中断,效率较高。中断响应时间是发出中断请求到开始进入中断处理程序;中断处理时间是从中断处理开始到中断处理结束。中断向量提供中断服务程序的入口
- DMA(直接主存存取):CPU 只需要完成必要的初始化操作。数据传输整个过程都由 DMA 控制器完成,在主存和外设之间建立直接数据通路,效率很高。在一个总线周期结束后,CPU 会响应 DMA 请求开始读取数据;CPU 响应程序中断方式请求是一条指令执行结束时
- 总线,计算机设备和设备之间传输信息的公共数据通道。总线由总线上的所有设备共享
- 总线分为:数据总线、地址总线、控制总线